PrefaceThis benchmarking exercise was part of a feasibility study for a Telecom User. This was one of my most important tasks during my last 6 months at Sun Software Practice, and through it I gained a lot of useful knowledge about MySQL. I wish here to show my special appreciation to my colleagues. Eric Li was technical account manager of the system team. He took care of platform issues and brought a lot of creativity to the project. Kajiyama-san is the MySQL evangelist for the Asian-Pacific area, and devoted ample time to addressing our special needs. He introduced some critical new features to the project and helped us solve many tough issues in a professional and timely manner.
InitiativesThe User is facing a vigorous challenge from competitors—and subsequently pressure from stockholders—expressing a need to squeeze more margin from a market which is becoming increasingly barren. The User hoped MySQL would bring them such benefits as:
The high costs of the current proprietary database regimen has been a sore point since day one: It has continuously eroded operating margins. The User sharply felt a need to find some way out from this constraint, in order to free up cash for promising new IT development projects.
- Open Source Model Adoption
The Open Source community has proven to be a source of truly mature innovations in recent years. The User expressed their hope that by using MySQL they could take advantage of some of this innovation and break the lock-in from the legacy database. In short, Open Source has for some time signaled the promise of increased real-world competitiveness.
- The Special Case of CRD (Call Detail Records) Cost Scaling
CDR databases are huge. Under our current legacy database pricing regimen, only 3 months of data can be stored. This is a limiting factor, and is about to meet the challenge of upcoming new government regulations which will require telecoms to keep 6 months of call details online. MySQL imposes no scaled costs on database size. Seeing also that the preponderance of CDR operations are READ-only (relatively risk-free) and that those DML operations are performed in batch mode (not real-time critical) the case for a migration to MySQL is further strengthened. However CDR functionality, itself, is mission critical, and therefore the User needs to consider both the cost savings and risks carefully before committing to migration.
Objectives
The proposes of these benchmarks are as follows:
- To evaluate the traits and performance characteristics of MySQL
Before deciding to use MySQL, the User needs to gain a clear understanding of MySQL, and know the pros and cons of any proposed migration paths. This information will help ensure that MySQL is used effectively.
- To ascertain specific applications to which MySQL may be especially pertinent
The user has a large applications profile, ranging from small task force scheduling to a mission critical BOSS system. We need to know which applications can reasonably use MySQL. Ideally, MySQL would not be limited to small and simple applications. Perhaps certain large systems with specific traits could also be good candidates for migration. The further up the chain we can safely and effectively go, the greater the cost savings.
- To collect sizing information for capacity plan and architecture design
Every database system has its own peculiar overhead costs and performance characteristics. Typically, the larger the data collections, the sooner one encounters idiosyncrasies. And it is these system traits that ultimately impact operating costs; for example in the area of backup and recovery. So we need to find out the traits of MySQL—coupled with varied storage engines—that could impact capacity plans and architecture designs for the target applications, some of which manage huge bases of information.
- To evaluate possible cost savings
In setting up a test database that is designed to parallel a production one, we can take pains to measure the total costs associated with using MySQL (servers, software license, storage, network etc.) with some precision, and compare these figures against those for the existing platform. In short, we can know with some certitude the possible cost savings from MySQL.
Testing Tasks
- Install, configure the environment
We configured two servers running Redhat ES 5 Linux and one storage server running Sun Open Storage, with 10 terabytes of capacity. The databases were configured using a master-slave replication architecture, detailed in the System Architecture section, below. To migrate data from the current CDR database, we created a virtual environment and installed Windows Server 2003 and SQLWays on the virtual machine. We used SQLWays to extract data from the current CDR database, and store it as plain, “flat” text files in a directory of the storage system. This is described in greater detail, below. This directory was network-shared with the Windows virtual environment and its host environment.
- Setup a LVM snapshot for backing up the database
We set up LVM on the Redhat servers and created a logical volume for a MySQL data directory. We used LVM to create a snapshot against the data directory and dump the data from the snapshot to the backup sets directories. With this technique, the impact of backup operations on MySQL database availability would be decreased.
- Install/Configure a monitoring system for collecting performance related data
In the beginning we used nmon to collect and show performance related information from the servers. Later, we used sar and ksar to simplify data collection and decrease overhead caused by nmon’s rather over-intensive data collection demon.
- Port data from the original database to plain text CSV files
We used SQLWays to extract data from the proprietary database into CSV files. These were kept in shared storage. We dumped 650 gigabytes; data only, no indexes. This is one month’s worth of PBX-generated records.
- Load data into MySQL and create indexes for each table
We used the "load data infile..." command to load data from the CSV files into MySQL tables and then regenerated indexes identical to those from the current production database.
Stress test with client applications to emulate DML from daily operations
Most of the DML operations performed on the CDR database are in batch mode. In the current production system, the procedure for stocking tables from the PBX with data that is then available for query is:
- load plain text data from the PBX into temporary tables. This step is basically identical to that described in the task described above; “Load data into MySQL…”.
- Use stored procedures to dispatch call data from the temporary tables into permanent tables—one table for each day, by date that the call was put. After the data has been loaded, the stored procedure regenerates indexes for permanent tables.
In implemented the above procedure, most of the effort would involve the rewrite of stored programs performing that second step. An easier task would be writing, testing, and introducing a processing step in which delimiters are inserted into raw PBX data: The MySQL load data command needs field delimiters, and data from the PBX currently lacks these. I wrote this program. It uses a property file that describes the delimiter character and field column widths of the source records.
- Stress test with a multi-threaded Java program that issues SQL statements to emulate concurrent database accesses
This was one of the most challenging parts of benchmark development; to generate SQL command executions that closely match those of a real production system. I looked for an off-the-shelf testing tool to do this—where SQL commands roll up data generated from several tables dynamically, based on the time period that the queries are covered—but couldn’t find one. I applied the following strategy to solve the issue:
- With help from the User’s CDR operation team, we logged the SQL commands hitting the production database over a period of time. We got a file containing more than 5112 timed SQL statements, reflecting database activity over a 10-hour period.
- I wrote a Java program to perform the stress test. It reads the file mentioned above, and uses that information to emulate a query regimen against the MySQL database undergoing testing. This Java program logs both the queries and system responses in a CSV file for later performance evaluation. The program runs in multiple threads to simulate multiple concurrent connections.
- Failover test with the MySQL master-slave architecture
We implemented a slave server as a failover database. The User needs the assurance that there will be no data lag between the master and slave servers in the event of failover. This needs to be tested.
There are 3 options for triggering failover with MySQL: Virtual IP, load balancer, and multiple hosts with the JDBC connection string. Due to resource constraints, and given that the last option was the cheapest, I only tested the last one. All I had to do was fill in a multitude of host names in the database host name parameter of the stress testing program while running the test.
- Backup the database with an LVM snapshot and then recover the database from the backup sets—including support for incremental backup/recovery
I configured a logical volume for the MySQL’s data directory, and used Zmanda Recovery Manager as a user interface for creating a backup from the snapshot which was configured in the 2nd task mentioned above. I also tested incremental backup with ZRM.
- Test the feasibility of point-of-failure recovery
For point-of-failure recovery, we need to recover the data from the full backup set stored in the backup target directory, and then apply the binary logs from the time after that full backup, up to the last records before the database crashed.
System Architecture
 As the graph on the left shows, we had:
As the graph on the left shows, we had:
- One Sun X4600 server as the master server; this server also acted as host server for the virtual machine running Windows Server 2003. SQLWays ran on the virtual environment for unloading tables from the existing database into CSV files. The server is equipped with 8 CPUs each with 4 cores, the server has 32 cores in total, and 32 gigabytes of RAM.
- One Sun X4450, with two 4-core CPUs (8 cores in total), and 8 gigabytes of RAM. The server acted as the slave server.
- One Sun 7410 storage server, equipped with 64 gigabytes of RAM. We configured the 20 terabytes of disk capacity into a mirror, making the effective available space 10 terabytes. This has 4 data channels, each with of 1 gigabit/second bandwidth. In the beginning only one channel was used. In later tests this was increased to 2 channels for tuning the performance of data loading. The storage is shared between the two abovementioned servers, and each one had their own partition.
The results
- Exporting data from original database to csv text files
SQLWays worked well, normally taking 1 hour and 45 minutes to export 22G bytes data (the data generated by the PBX in one day), I found that the job was I/O bound when exporting data with a single task thread: There should not be much room for improvement.
- Loading data into MySQL and creating table indexes
We started with MySQL 5.1.41, with a built-in Innodb storage engine. We tested both Innodb and MyISAM tables, we found that loading and indexing the 22G bytes data—generated by the PBX in a single day—into Innodb tables took more than 24 hours: A totally unacceptable arrangement! We tuned the “my.cnf” option file, increasing the innodb_buffer_pool_size and changing the flush method to O_DIRECT. This shorted the data processing task to 12 hours 32 minutes; still significantly slower than the current legacy database which only requires around 8 hours to load data into temporary tables and then dispatch them to the permanent tables. Most daunting of all was the thought that if the database crashed while loading such a large amount of data, the time needed to recover from that failure would be very long when restarting the database; much more than the time needed to load the data.
Thanks to the new Innodb plugin storage engine, we found a way out. We used Innodb 1.0.6. set the file format to "Barracuda". The following table shows the results. The time for loading the 22 gigabytes of data shrunk to 42 minutes, with an additional 1 hour and 47 minutes to create the indexes—a tremendous improvement! Furthermore, loading and creating indexes with MyISAM tables provided even more stability. It took 51 minutes to load data, and index generation needed less than 278 minutes. Further details on our database tuning exercise will be narrated in the next post of this blog.
Although the Innodb plugin performed much better than the legacy database, it’s still quite annoying to have to wait a such a long time in the recovery stage when restarting MySQL from a crashed state while loading large amounts of data. And as most of the DMLs in the CDR system are performed by a batch job, there is no need to incur data integrity overhead on transaction, so we decide to use MyISAM in the later tests.

- Stress testing with client application to emulate daily DML operation tasks
Because the raw data from the PBX has no separators, and the MySQL load data command needs delimiters to elucidate the fields, I wrote a program to add separators based on a properties file that can be edited by the users. This file contains two types of info, 1) a specification of the delimiter character, and 2) column positions for each delimiter.
Apart from loading data, almost all the DMLs are performed by a set of stored procedures which dispatch data in the temporary tables to permanent tables, with a new set of tables generated for each day. I rewrote the current stored procedures from the existing proprietary database language to MySQL's ANSI SQL compliant store procedures. The syntax converting job was not as hard as I thought it would be. After the learning experience of the first rewrite, the job became routine and easy. However, there were dynamic SQLs that created tables and indexes dynamically; it took a while to figure out how to implement them via local variables and call procedures with the variables as parameter. Details regarding this conversion experience will be described in a subsequent blog entry.
Most of the DMLs in the dispatching stored procedure are insert commands. The insert speed of MySQL stored procedures is amazing: It only took 57 minutes to dispatch 66 gigabytes/210 million rows of data (3 days worth of PBX data), and 3 hours 20 minutes to dispatch the data to tables, compared with more than 5 hours to dispatch a single day's data in the existing system; it's a significant leap!
Summing up the time required for the whole procedure –adding separators, loading the CSVs to temporary tables, and dispatch the temporary table to permanent tables and create indexes , 2 points stand out:
- In terms of time required, there is not much difference between creating indexes prior to or after the tables have been loaded with data.
- It took 15 hours and 20 minutes to go through the entire process dealing with 3 days of PBX data: That’s an average of 5 hours and 7 minutes per day. This is superior to the present regime. Furthermore, the User has indicated that they will be able to add field separators on the PBX side at record generation time: This means it will be possible to shorten our process by 3 hours 20 minutes, thereby needing only 1 hour and 20 minutes. This would be 6 times faster than the existing database!

- Stress testing with multi-threaded Java program that issues SQL statements to emulate concurrent database access
As the following table shows, we ran the stress test program with 1 thread, 4 threads, and 8 threads, to simulate 1, 4, and 8 concurrent connections, respectively. The time needed to run the test was 3 hours and 5 minutes (11082 seconds), 11 hours and 14 minutes, and 11 hours and 21 minutes, respectively. The 1- and 4-thread trials had only 1 channel of 1-gigabits/channel connectivity. I observed there was IO contention between sorting in temp directory and table accessing, so I added one more channel (2 channels in total) when running the 8-thread test, and assigned the “tempdir” to the new partition that added by the new channel. This should be the reason for the results from the 4-thread and 8-thread tests being about the same (compare the results between 1 thread and 4 threads).

The following graphs show that the maximum response times for each test ranged between 420 to 546 seconds. Apart from the 6-fold increase between 1 thread and 4 threads, there is not much variation.

As the number of threads rises further to12 there are few exceptions shown in the response log, so it’s safe to say the request load ceiling of the database should between 8 to 12 threads. I use several PCs to run the stress test program, where the SQL requests return a few rows. I think any performance factors owing to the test tools and network bandwidth are negligible, and can be ignored.
The SQL statements used were taken from real-world database logs, containing database hit traffic over a 10 hour period. When I ran the test with 8 threads over 17 hours the total number of SQL requests the database had processed was 40896 (5112 * 8). In point of fact, these test cases were much more rigorous and demanding than a real situation could ever be. When the response times for the 5112 SQL statements were checked, I found that SQLs that return 0 to 1000 rows are returned within 3 seconds. But there were 63 cases where the request had to return 497848 to 64415 rows, response times fell between 25 to 408 seconds. As most of these large result set SQL requests occur consecutively, this was a notable bottle neck in the test. Out of curiosity, I tried distributing these larger request statements to temporally disparate points in the SQL test-bed command file, and congestion on these larger commands weren’t much different—pretty much returning the same performance stats under the 4- and 8-thread test regimens.
In response to this information, the User expressed concern that with a limited number of concurrent connections, these larger transactions would negatively impact access by the flurries of smaller transactions. So I decided to do some special testing to determine MySQLs behavior under a regiment in which both large and small transactions vie for attention. I derived two command files from the original real-world file; one containing only 63 large-transaction commands, and another containing only 100 small-transaction commands. I ran both command files simultaneously. The results are shown in the following table and graph. The number of threads does not appear to be much of a factor: The small transaction set finishes quickly regardless. However, the response times for the large result requests increased linearly with the thread count, as the following table and graph shows. When the threads number increased from 12 to 28, the maximum response time increased from 640 seconds to 1138 seconds, and the run durations increased from 1 hour and 42 minutes to 2 hours and 41 minutes.
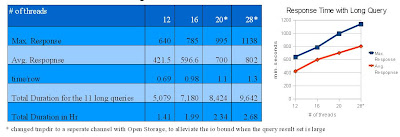
I noticed that MySQL uses temp directory to deposit its temporary tables for sorting rows requested by transactions. It occurred to me that this whole enterprise may have been haunted by a simple disk I/O bottleneck, related to a configured limitation in the number of available storage IO channels. In cases where the number of threads exceeded 20, I configured additional IO channels and mapped the "tempdir" to the mount point of the new IO channel. It fixed the problem! I was able to elevate the number of concurrent connections to 28 with no exception in the log file.
- Failover testing with the MySQL master-slave architecture
I tested the failover by assigning multiple host names in the connection string of the MySQL JDBC driver. I ran the stress test program with 2 host names (one for the master server, one for the slave) in the host name parameter. It showed that when I shut down the master server while running the test program, currently connected threads cleanly threw database exceptions on the console. Threads attempting to connect after the shutdown were “failed overed” and queried the slave server properly. Further improvements in connection exception handling should be readily obtainable by simply adding code in the exception handler section of the client programs to failover the connection to the 2nd database.
- Backing up the database with LVM snapshot and recovering the database from the backup sets; incremental backup/recovery also included
Because MySQL’s built-in backup solution is very limited, and there is very significant overhead to backing up large volumes of data, augmenting the backup with a snapshot would be a good idea. There are OS level snapshot solutions such as ZFS for Solaris, and LVM for Redhat, and on the storage level snapshot, you have thin provisioning, iSCSI, and NFS which are supported by Sun Open Storage. OS snapshot solutions are easier to integrate into Backup tools such as Zmanda.
I used LVM for the snapshot and ZRM to manage the backup, but there is a pitfall for novice Users: If you wish to create a dedicated disk for backup set storage, apart from the logical volume for the MySQL’s data directory, it’s necessary to create another logical volume for the backup set storage. Otherwise erroneous recursive inserting on the same logical volume kicks in, and space is quickly exhausted.
ZRM performed well both in full backup and incremental backup, but when I tried to recover the database from the time before the full backup started to the time that an incremental backup had been performed, the ZRM console indicated a duplicate data insertion error. I think this might have been caused by data from before the full backup in the binlog having been applied. I have not discussed it with Zmanda yet, but I think it could be solved by 1) first generating a log switch before the full backup, then 2) removing the binlog files that contain data from before the full backup when the full backup is finished.
- Testing the feasibility for point-of-failure recovery
With ZRM's nice user interface, it is easy to do a point-of-failure recovery with full backup and binlog. I think that in a production environment, storing binlog files in a volume separate from the data directory would be safer.
ConclusionMySQL is unique for its plugable storage engine. This gives Users freedom to tune the database to the characteristics of the applications. For applications with few online DMLs and a lots of queries (e.g., CDR), we can use MyISAM for the tables storage engine to take advantage of the low overhead and the easy maintenance and operation. On the other hand, for tables requiring online transaction performance, while carefully maintaining data integrity, we can use Innodb as the storage engine; the higher overhead is warranted by the application.
As Innodb evolves, we can expect to see further performance benefits via a faster data loading speed. Benchmarks indicate a 5-fold speed improvement, which could cut total operating time from 12.5 to 2.5 hours. I believe that with MySQL 5.5, the performance should improve yet further, and I am looking forward to trying it out in another set of benchmark tests.
 As the graph on the left shows, we had:
As the graph on the left shows, we had:

 I noticed that MySQL uses temp directory to deposit its temporary tables for sorting rows requested by transactions. It occurred to me that this whole enterprise may have been haunted by a simple disk I/O bottleneck, related to a configured limitation in the number of available storage IO channels. In cases where the number of threads exceeded 20, I configured additional IO channels and mapped the "tempdir" to the mount point of the new IO channel. It fixed the problem! I was able to elevate the number of concurrent connections to 28 with no exception in the log file.
I noticed that MySQL uses temp directory to deposit its temporary tables for sorting rows requested by transactions. It occurred to me that this whole enterprise may have been haunted by a simple disk I/O bottleneck, related to a configured limitation in the number of available storage IO channels. In cases where the number of threads exceeded 20, I configured additional IO channels and mapped the "tempdir" to the mount point of the new IO channel. It fixed the problem! I was able to elevate the number of concurrent connections to 28 with no exception in the log file.